PacificA:微软设计的分布式存储框架分析
本文主要阅读下面2篇文章整理完成 (有歧义以原文为主):
系统框架
整个系统框架主要有两部分组成:存储集群和配置管理集群。
存储集群:负责系统数据的读取和更新,通过使用多副本方式保证数据可靠性和可用性;
配置管理集群:维护副本信息,包括副本的参与节点,主副本节点,当前副本的版本等。
数据被存储在数据分片上,数据分片实际上是数据集合,每个数据分片的大小基本固定,在存储节点上,数据分片表现为磁盘上的一个大文件。而数据分片也是多副本的基本单位。
配置管理集群维护的其实是分片的副本信息(分片位于哪些节点)。数据分片的副本称之为复制组(Replication Group)。因为每个存储节点上会存在众多的数据分片,因此,每个存储节点会位于多个复制组中。
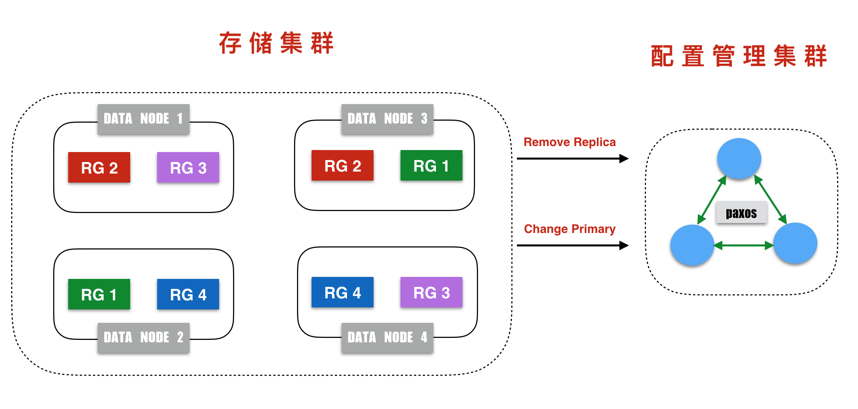
配置管理集群维护所有分片的位置信息,配置管理集群使用Paxos协议维护该数据的一致性。存储集群以配置管理集群维护的分片位置信息为准。
设计目标
High scalability, availability and throughput
Flexibility and configurable
Necessary features, extensibility
Correct, simple and clean designs
Good user experiences
PacificA是一个读写都满足强一致的算法,它通过三个不变式保证了读写的primary的唯一性,读写的强一致性,故障恢复的可靠性。
它把数据的一致性和配置的一致性分开,使用额外的一致性组件(Configuration Manager)维护配置的一致性,结合lease机制保证了Primary Invariant,使得在同一时刻有且仅有一个primary。 update操作时,要求所有的secondary均prepare当前update,primary commit当前update,保证了Committed Invariant, 使得读操作可以获取到最新数据,primary故障时,secondary也有全量的数据。
故障恢复机制保证了当secondary被选为primary时,其commit包含之前primary或secondary的commit,保证了Reconfiguration Invariant,使得在故障恢复后数据不会有丢失。
数据分片
本地存储设计要点:
- Sequential IO
- Immutable files(append)
- Easy to take a snapshot
- Easy to handle failures
- Continue to update the data when we do query

系统模型和前提条件
- No Byzantine Failure.
- Fail-stop and messages, when delivered, are delivered correctly.
- Network is unreliable (may lose, reorder, duplicate messages, may partition)
一致性保证
Strong Consistency
- A total ordering of all requests yields the same responses that client received, reads must return the committed most up-to-date values
Sequential Consistency
- allows reads to return outdated values
Weak Read Consistency
- Read can return results of even uncommitted operations
复制协议
- Primary/Backup protocol
- Two-phase protocol
- One-phase protocol
Primary/Backup protocol
Two-phase protocol

Prepared and committed list

pacificA副本数据使用主从式框架来保证数据一致性。分片的多个副本中存在一个主副本Primary和多个从副本Secondary。所有的数据更新和读取都进入主副本,当主副本出现故障无法访问时系统会从其他从副本中选择合适的节点作为新的主。
在pacificA协议中,每个节点都维护
数据更新的流程如下:
- 更新记录进入主副本节点处理,为该记录分配Sn(Serial Number),然后将该记录插入prepare list,该list上的记录按照sn有序排列;
- 主副本节点将携带sn的记录发往从节点,从节点同样将该记录插入到prepare list;
- 一旦主节点收到所有从节点的响应,确定该记录已经被正确写入所有的从节点,那就将commit list向前移动,并将这些消息应用到主节点的状态机;
- 主节点提交后即可给客户端返回响应,同时向所有从节点发送消息,告诉从节点可以提交刚刚写入的记录了。

通过上面的分析可以知道,commit list和prepare list必然满足以下条件:
Commit Invariant: Let p be the primary and q be any replica in the current configuration, committed q ⊆ committed p ⊆ prepared q holds.
所有的读需要全部发往主节点,这是因为客户端来读时,主节点有可能尚未将commit消息发送至从,因此,如果读从节点可能会无法获取最新数据。当然,如果应用能够忍受一定的窗口,那读从也无所谓。
想到一个异常情况,当update执行过程中,primary挂掉了,导致更新失败,secondary已经被prepare了update,这时一个secondary被选为新的primary,将其所有的update commit,那之前失败的update操作数据不就出现在了数据中,导致与预期不符?
pacificA算法中一个primary或secondary是一个数据实体,不应该是一个执行实体,所以当primary挂掉后,update任务不会执行失败,而是等待选出新的primary,并在其上commit这个update,保证不会出现数据不一致的情况
P/B Protocol(Failure Scenarios)
Configuration
Be consisted of primary and several backups
Has a view number which increases by one each time the configurations changes.
Master(God) keeps the authoritative, most up-to-date configurations of all the groups.
pacificA通过契约(lease)的方式来进行primary和secondary间的互相检测。primary会定期(lease period)向各节点请求契约,如果某个节点没有回复,则说明该节点已经故障,primary会向Configuration Manager请求移除该secondary。 如果过了(grace period), 一个secondary没有收到primary的请求,则认为primary故障,该secondary会向Configuration请求移除Primary,并将自己设置为primary。这里要注意
- 当多个secondary均发现primary故障,则按照first win原则,先请求的成为primary
- 当出现网络分区时,primary会要求剔除secondary, secondary要求剔除primary,但由于lease period< grace period,可以保证primary先于secondary发现故障,并将secondary剔除
系统运行过程中难免出现节点宕机离线等诸多异常。如何保证在节点异常情况下协议的正常运行是分布式系统设计中的关键问题。pacificA是一种强一致协议,通过主节点来维护多副本数据一致性。因此,需要确保每个副本的唯一主,避免二主问题的发生就非常关键。
pacificA使用了lease机制来保证不会产生二主问题。主节点与从节点维护心跳信息:主节点定期发送心跳,只要从节点响应该心跳,主节点就确定自己还是主。对于以下两种可能的异常:
- 如果主节点在一定时间内(lease period)未收到从节点对心跳的回应,那主节点认为从节点异常,于是向配置管理服务汇报更新复制集拓扑,将该异常从节点从复制集中移除,同时,它也将自己降级不再作为主;
- 如果从节点在一定时间内(grace period)未收到主节点的心跳信息,那么其认为主节点异常,于是向配置管理服务汇报回信复制集拓扑,将主节点从复制集中移除,同时将自己提升为新的主。
分析可知,只要lease period <= grace peroid,就不会产生二主问题,因为:
- 假如主从之间出现网络分区。只要lease period <= grace peroid,主必然先检测到从没有回复的事件,于是他开始停止作为主服务,并且通知配置管理服务;
- 由于lease period <= grace peroid,那么从节点检测到主节点异常则是在主节点停止作为主以后,此时该副本集是不存在主的,因此,必然不会产生二主现象。
为什么主在检测到从节点异常时需要停止自己作为主的身份?
如果不这样有可能会出现多主情况。分析一下,主节点不停止自己作为主,继续对外提供更新服务,而直接向配置管理服务汇报从复制集中移除从节点的消息M1,而从节点经过一段时间后向配置管理服务汇报移除主节点并将自己提升为新主的消息M2,但是由于网络传输的不确定性,配置管理服务可能会先处理M2,于是问题来了,这时候就产生了两个主,破坏系统的强一致性。
使用租约机制保证一致性是众多分布式系统的标准做法,例如GFS、Bigtable等。但是诸如GFS、Bigtable都是从一个集中式服务中申请lease,而pacificA则是一种去中心化式的租约机制。
另外,主从之间的数据流动也天然发挥了心跳信息的功能,因此,只要主从之间有数据交换,就可以无需发送心跳。
secondary故障
当一个scondary故障时,primary在向该secondary发送lease请求时会超时,primary向Configuration Manage发送Reconfiguration请求将该secondary从Configuration中移除
primary故障
当primary故障时, secondary在超过grace period没有收到primary的请求,就会向Configuration Manager发送Reconfiguraiont请求
要求将primary从configuration中移除并将自己选为primary。多个secondary竞争成为primary时,遵循first win原则。
当一个secondary被选为primary后 ,它会向所有的secondary发送prepare请求,要求所有的sencodary均以其pareparedList为准进行对齐,当收到所有secondary的ack后,primary将自己的commit point移动到最后,这个时候primary才能对外提供服务。
网络分区的场景
网络分区场景下,primary认为secondary故障,secondary认为primary故障,但由于lease period小于grace period,所以primary会先与secondary发现故障,并向Congfiguration Manager发送请求移除secondary
新节点加入
新节点加入时,首先会先成为secondary candidate, 然后追平primary的preparedList,然后申请成为secondary。还有一种情况是之前故障的节点恢复加入,这个时候会复用之前的preparedlist并追平secondary的preparedlist, 然后申请成为secondary。
Primary Invariant
在pacificA算法中,要保证primary不变式Primary Invariant,即
- 同一个时刻只有一个副本认为自己是primary
- configuration Manager也认为其是primary。 从前面的故障恢复可以看到pacificA算法通过lease(契约)机制保证了这个不变式
Reconfiguration Invariant
重新配置不变式:当一个新的primary在T时刻完成reconfiguration,那么T时刻之前任意节点(包括原primary)的committedList都是新的primary当前committedList的前缀。
该不变式保证了reconfiguration过程中没有数据丢失,由于update机制保证了任意的sencondary都有所有的数据,而reconfiguration重新选primary要求新的primary commit其所有的prepareList,因此这个不变式可以得到保证。
参考资料
https://www.zhihu.com/question/59320850/answer/1578135865
https://blog.51cto.com/u_15060462/2649440
https://helloyoubeautifulthing.net/blog/2019/01/31/pacifica-notes/
https://zhuanlan.zhihu.com/p/260005664
https://www.microsoft.com/en-us/research/wp-content/uploads/2008/02/tr-2008-25.pdf
http://bos.itdks.com/2e8c552646f44c66b038cb76fd728167.pdf